Text-Hermeneutic Multilevel Similarity Exploration
Was ist THeMSE?
THeMSE ist ein visuelles Textanalysewerkzeug zur Exploration von Textähnlichkeiten im Close und Distant Reading, das im Kontext des Projekts Das Buch der Briefe der Hildegard von Bingen. Genese – Struktur – Komposition von Marina Lehmann, Markus John und Andreas Kuczera entwickelt wurde. Mithilfe von THeMSE können die Briefe Hildegard von Bingens aus den Handschriften R, Wr und M untersucht werden. Momentan sind aus R 282 Briefe enthalten, aus Wr 43 Briefe bzw. 44 Briefe aus M. Alle Texte liegen sowohl in einer normalisierten als auch in einer lemmatisierten Fassung vor. THeMSE bietet einerseits die Möglichkeit, handschriftenübergreifende Textähnlichkeiten zu entdecken (Überblicksebene mit Heatmap), andererseits können auch handschrifteninterne Ähnlichkeiten identifiziert werden (Explorationsebene mit Fingerprints).
Textähnlichkeit
Da Textähnlichkeit auf verschiedene Arten definiert werden kann, stehen drei verschiedene Verfahren zur Auswahl, um handschriftenübergreifend die Ähnlichkeitswerte pro Briefpaar zu ermitteln: Levenshtein, ein Bag-of-Words-Modell mit TF-IDF-Gewichtung (kurz: TF-IDF) und doc2vec. Levenshtein arbeitet zeichenbasiert und ermittelt anhand der übereinstimmenden bzw. abweichenden Zeichen die Editierdistanz zwischen zwei Texten, auf deren Grundlage die Ähnlichkeitswerte berechnet werden. Das TF-IDF-Verfahren und doc2vec arbeiten vektorbasiert. Bei TF-IDF werden die Dokumentvektoren anhand der gewichteten Worthäufigkeiten ermittelt, bei doc2vec ergeben sie sich aus den Wortkontexten. In beiden Fällen wird der Ähnlichkeitswert über die Kosinusähnlichkeit zwischen den Dokumentvektoren berechnet.
Features
Überblicksebene: Heatmap
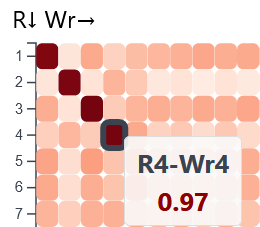
Für den handschriftenübergreifenden Vergleich steht eine Heatmap zur Verfügung, die jeweils die Briefe aus zwei Handschriften gegenüberstellt. Pro Briefpaar wird ein Ähnlichkeitswert errechnet und farblich kodiert. Die Farbintensität spiegelt die Höhe des Ähnlichkeitswerts wider: 0 – keine Ähnlichkeit, 1 – maximale Ähnlichkeit.
Über ein Menü können verschiedene Einstellungen bezüglich Manuskriptkombination, Textform (lemmatisiert oder normalisiert) sowie zum Textvergleichsverfahren (Levenshtein, TF-IDF, doc2vec) vorgenommen werden. Mit Klick auf den Button "Heatmap erstellen" wird gemäß den Einstellungen eine Heatmap generiert.
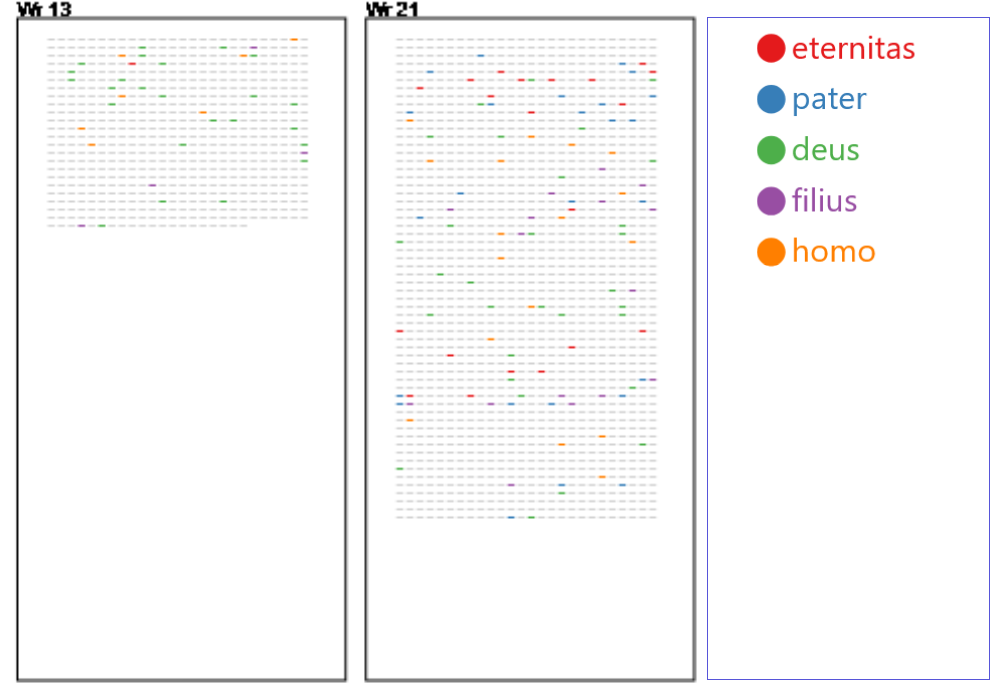
Explorationsebene: Fingerprints
Für die handschrifteninterne Datenanalyse steht die Explorationsebene mit der Fingerprint-Ansicht bereit. Über eine Begriffssuche können thematische Ähnlichkeiten zwischen den Briefen innerhalb einer Handschrift identifiziert werden. Diese Ebene bietet folgende Suchmöglichkeiten:
1. Begriffssuche: In einem Suchfeld können Begriffe eingegeben werden. Diese müssen durch ein Komma voneinander getrennt sein.
2. Begriffsvorschläge: Basierend auf einem Startbrief können Begriffsvorschläge für die Suche generiert werden. Die Vorschläge entsprechen den 20 charakteristischen Begriffen für den ausgewählten Brief, d.h. den 20 Begriffen mit den höchsten TF-IDF-Werten. Diese Suchform eignet sich für eine explorative Analyse.
3. Begriffe aus der Merkliste: Interessante Begriffe und Begriffskombinationen können in eine Merkliste eingetragen und für eine spätere erneute Suche abgespeichert werden.
Darüber hinaus können verschiedene Sortier- und Filtereinstellungen vorgenommen werden. Neben der Auswahl des Manuskripts, in dem gesucht werden soll, kann auch eine Mindestanzahl an Suchtreffern angegeben werden. Möchte man bei mehreren Suchbegriffen nur die Briefe berücksichtigen, die alle Suchbegriffe enthalten, kann die Kombinationssuche aktiviert werden.
Startet man die Suche, werden die Suchtreffer in Form von Fingerprint-Matrizen angezeigt, abstrakte Repräsentationen der Briefe, in denen die Suchbegriffe farblich hervorgehoben werden. So entsteht für jeden Brief ein individuelles Profil. Es können maximal 8 Begriffe gleichzeitig gesucht werden. Die Reihenfolge der Fingerprints lässt sich beeinflussen. Es ist sowohl möglich, die Fingerprints nach der Anzahl der Treffer als auch nach der Anzahl der Wörter zwischen den Treffern zu sortieren.